The Right Way
If you've ever searched for a diagram that explains Event Sourcing, you may have found many images, but most of them are confusing or simply incorrect. Despite claims that Event Sourcing is difficult, many people who have this opinion have never actually tried it or made mistakes during implementation.
Eventuous does not claim to be the ultimate authority on the subject. In fact, the library's code is based on previous successful implementations in production and reflects a specific approach to Event Sourcing.
However, in response to the demand for guidance on doing Event Sourcing correctly, we have a solution for you here.
How Eventuous does it
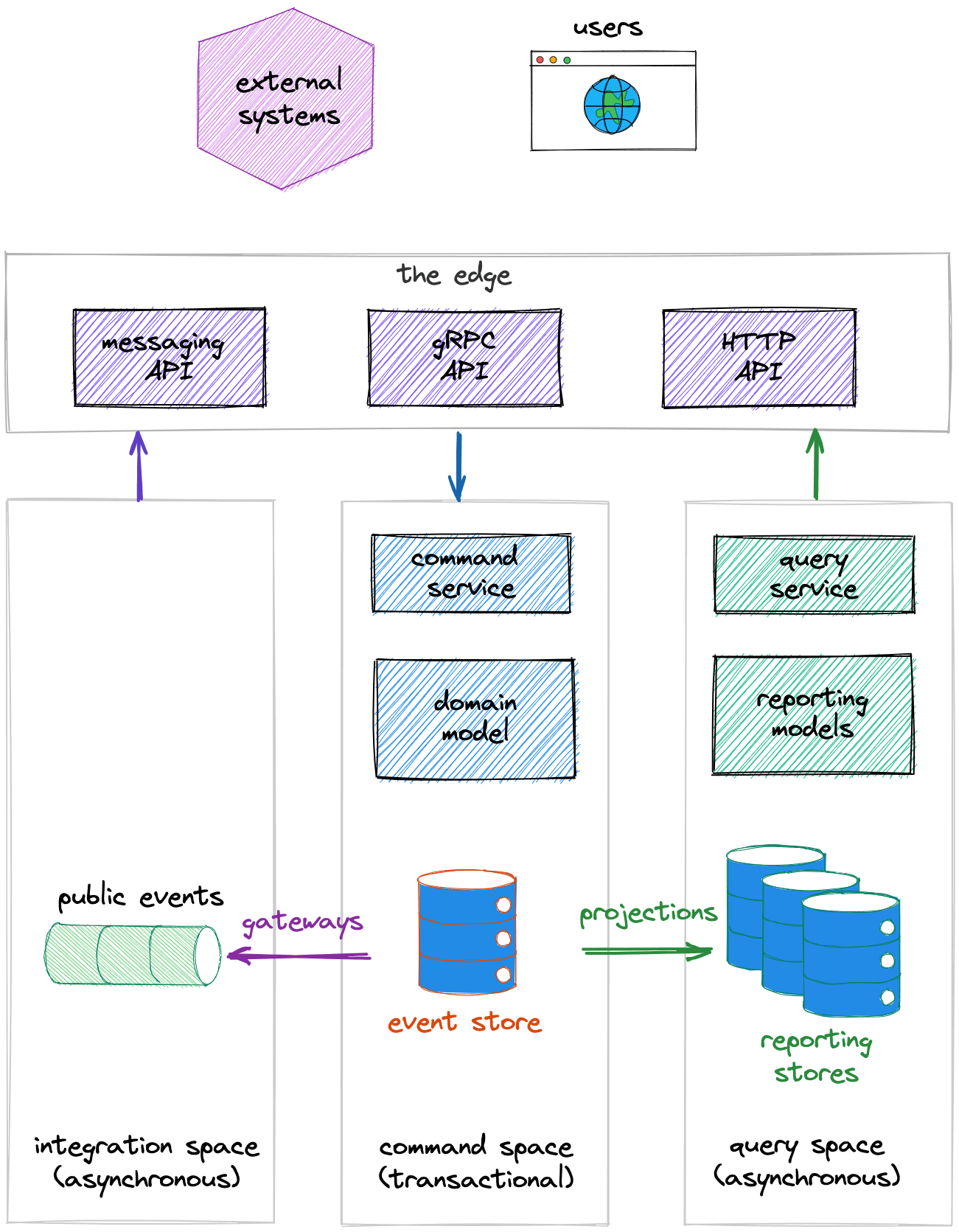
The core of the application is the domain model, which contains essential business functionality that is encapsulated in domain objects. This is the only place where business logic is implemented.
The command services receive commands from the external environment and forward them to the domain model. They are responsible for validating commands, calling domain object functions, and managing persistence.
The newly generated events are stored in the event store, which requires a database capable of pushing new events in real-time to subscribers.
The event store pushes the stored events to subscribers. Subscribers can generate integration (public) events, for which the Gateway component in Eventuous is responsible. Another type of subscriber can project events to other databases for query or analytics purposes. Eventuous supports projecting events to MongoDB, but you can project to any database using custom event handlers.
Please refer to the diagram below for a complete understanding of the process.
What's wrong with those other diagrams?
Several diagrams that claim to explain Event Sourcing and its implementation often have similar problems, such as:
- Using a bus to propagate domain events to read models
- Introducing unnecessary components and complexity to the diagram
- Not using domain events as the source of truth for the domain model state
- Confusing Event-Driven Architecture (EDA) with Event Sourcing
Let's examine these issues.
Event bus
Message brokers can be useful for integrating (micro)services through asynchronous messaging, rather than relying on RPC calls. However, the integration aspect is separate from Event Sourcing. Domain events enable message-based integration, but it's not a requirement.

Using a broker to propagate events to reporting models (read models, query side, etc.) can lead to:
- Out of order events: In order to project events to reporting models, it's important that they are processed in the same order as they were produced. Not all message brokers provide this guarantee.
- Two-phase commit: As the database storing the events and the message broker are two separate components, making a single transaction that persists an event and publishes it to the broker can be difficult. One of these operations may fail, causing the system to become inconsistent. While the Outbox pattern can mitigate this issue, its implementation is often more complex than the core system itself.
- Replay: Message brokers are often used for integration, meaning that there are event consumers that react to published events. Unlike reporting models, integration side effects are not idempotent and can't be expected to happen multiple times. When replaying events from the event store to rebuild a single reporting model, other consumers will also be affected and may produce unwanted side effects.
Avoid publishing events to a message broker when handling commands. Instead, ensure that the event store database can support real-time subscriptions and subscribe directly to the event store.
Publishing events to a message broker from a subscription is a valid scenario. Eventuous provides a component called Gateway for that purpose. However, it's recommended to project events by subscribing directly to the event store, rather than building reporting models by consuming from a broker unless it's an event log-based broker like Apache Kafka, Apache Pulsar or Azure Event Hub.
Using reporting database as system state
Using Reporting Database as System State Event Sourcing is a consistent persistence mechanism. An event is appended to the aggregate stream, and the aggregate state is restored by reading these events, which are atomic, consistent, isolated, and durable (ACID).
However, some articles describe Event Sourcing as simply storing events to an ordered log, without using those events as the source of truth. Instead, they project events to another store outside the transaction scope and call it Event Sourcing, but this method does not guarantee consistency. This can result in a delay between when an event is stored and when the state change is reflected in the other database. The latter serves as a reporting model but is not a consistent storage for the system state. In a genuine event-sourced system, the state of any object can always be obtained from the event store and is fully consistent. In a projected store, only a particular state projection is available, which may not be up-to-date. While this is fine for reporting models, it's not suitable for decision-making.
Handling a command results in a state transition of one domain object and the entire system. It's important to operate with a consistent system state when making decisions to execute a command.
Event-Driven vs Event Sourcing
Event-Driven Architecture (EDA) is a software design pattern where events, or changes in state, serve as the driving force behind the behavior and interactions of the system's components. In an event-driven system, components communicate with each other by producing and responding to events, rather than by making direct calls to one another. The events are usually managed by a message broker, which is responsible for distributing the events to the appropriate components.
Event Sourcing is a way of persisting the state of a system by storing a sequence of events that represent changes in state, rather than just storing the current state. In event sourcing, the current state of the system is derived from the events that have been recorded.
Although Event Sourcing and EDA are often used together, they are not dependent on each other. It is possible to have an event-driven system without using Event Sourcing to persist state, or an event-sourced system that does not distribute events to the outside. Event Sourcing provides a way to persist state, while EDA is about integrating system components using events. Both Event Sourcing and EDA have their own benefits and trade-offs, and the choice of whether to use one, both, or neither will depend on the specific requirements of the system being developed.