Consume pipe
Pipes and filters
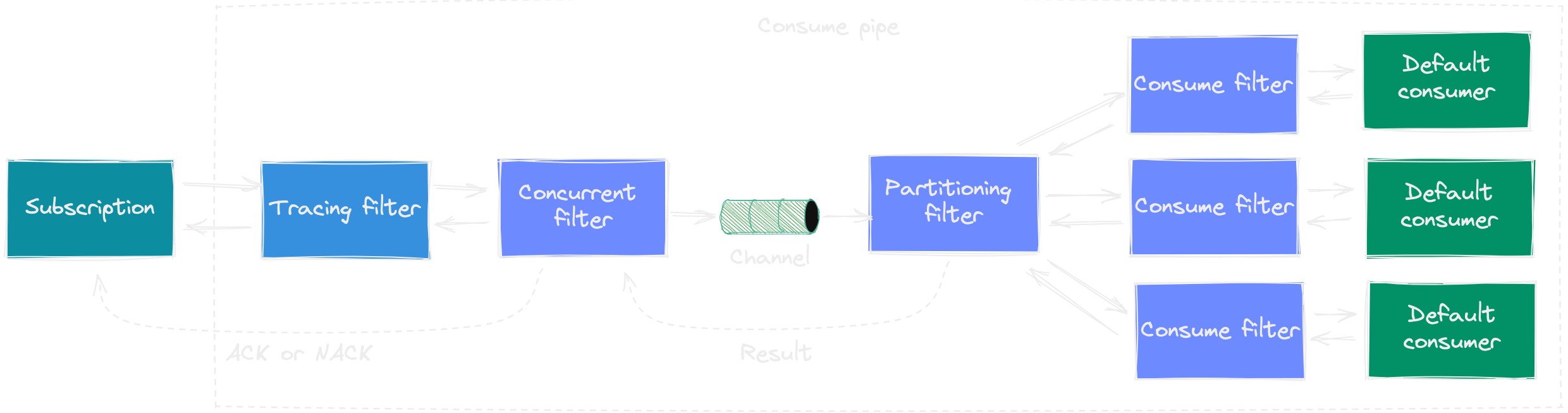
When a subscription gets a message from the transport, it will create a consume context with the message itself, and some contextual information like message id, message type, subscription id, etc. Then, it will pass it over to the consume pipe. A pipe is a set of filters, which are executed sequentially, like middlewares. Each filter can do something with the context, and then calls the next filter. The process continues until there are no filters left. By that time, the message is considered consumed, and the pipe finishes.
Eventuous consume pipe can be customised by adding filters to it, but normally you'd use the default pipe, which can be visualized like this:

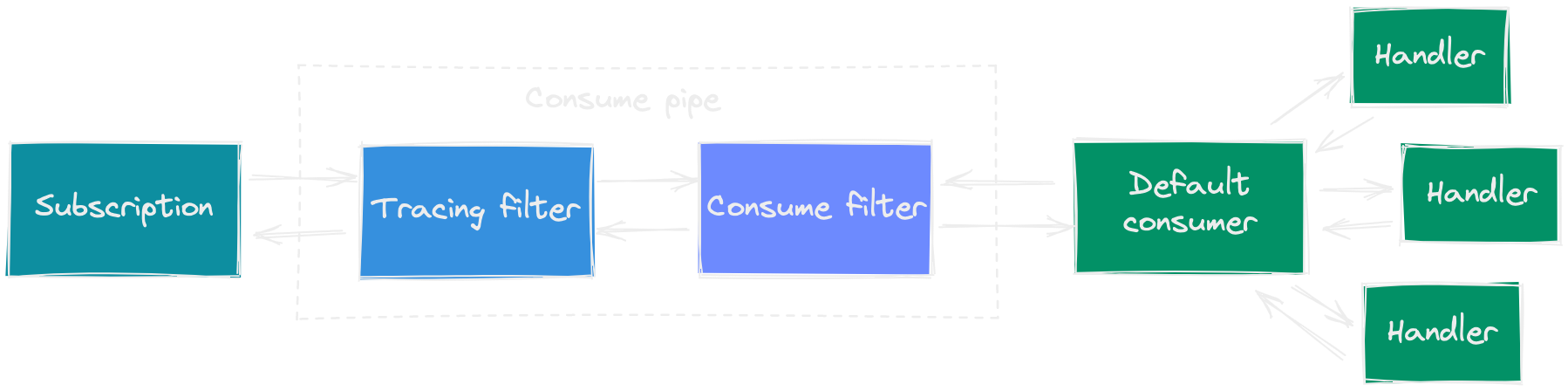
Some subscriptions conditionally or unconditionally add filters to the pipe, when they detect the default pipe. For example, EventStoreDB catch-up subscription might add the concurrent filter and partitioning filter, and RabbitMQ subscription uses the concurrent filter.
Available filters
Eventuous has two interfaces for filters, but all the provided filters are based on ConsumeFilter and ConsumeFilter<T> base classes. There, <T> is the context type, as some filters can only process certain context types. The validation of filter vs context type matching is done when the pipeline is constructed, so it won't fail at runtime.
Out of the box, you can find the following filters:
ConsumerFilter: (mandatory) the final filter in the pipe, which hosts the consumerMessageFilter: (optional) allows filtering out messages based on context data (message type, meta, payload, etc.)TracingFilter: (optional) traces the event handling process, added by default when diagnostics aren't disabledConcurrentFilter: (optional) allows splitting message processing from the subscriptionPartitioningFilter: (optional) allows parallel message processing with partitions
Consumer filter
The consumer filter holds an instance of the message consumer. By default, Eventuous uses the DefaultConsumer, and it doesn't require any configuration. You can override that using the UseConsumer<T>() function of the subscription builder when you register a subscription.
The default consumer Acks the message when all the handlers processed the message without failures, and at least one handler didn't ignore the message. It Nacks the message if any handler returned an error or crashed. Finally, it will ignore the message if all the handlers ignored it. How the message handling result is processed is unknown to the consumer as this behaviour is transport-specific. Each subscription type has its own way to process the message handling result.
When building a custom consumer, you'd need to include similar event handling result logic into it.
The consumer filter is a mandatory filter that should be the final filter in the pipe. When you register a subscription, the consumer filter is added to the pipe by default.
Message filter
The message filter can be used to prevent some messages from going down the pipe by filtering those messages out. When constructed, it needs a single constructor argument, which is a filtering function. The function gets an instance of IMessageContext, so it can use all of its available properties to filter messages. When the message is filtered out, the filter will mark it as ignored.
Example:
builder.Services.AddSubscription<StreamSubscription, StreamSubscriptionOptions>(
"nonFooSubscription",
cfg => cfg.AddConsumeFilterFirst(new MessageFilter(x => !x.MessageType.StartWith("foo")))
);
Such a subscription will ignore all the events that have the type starting with "foo".
Tracing filter
The tracing filter gets added automatically when Eventuous diagnostics is enabled (or, not disabled, as it's enabled by default). Read more about Eventuous tracing in the Diagnostics section.
Concurrent filter
When using the concurrent filter, the pipe gets separated in two parts: before the concurrent filter and after it. The filter itself creates a channel of a given size (100 by default), where it puts all the messages in order. Then, the pipeline returns to the subscription as if the message was already consumed. A parallel process fetches messages from the channel continuously, and sends them to the second part of the pipe where messages actually gets consumed.
Because of such a split, the result returned to the subscription doesn't contain the actual handling result. Therefore, the concurrent filter can only be used in combination with DelayedAckConsumeContext. It's the responsibility of a subscription to create such a context type, so only some subscription types support using the concurrent filter. This context type has two additional functions to Ack (Acknowledge function) or Nack (Fail function) each message. The subscription provides specific implementations of those functions. For example, an EventStoreDB catch-up subscription would commit the checkpoint when the event is acknowledged. The filter calls these functions itself, based on the result returned by the second part of the pipe (delayed consume).
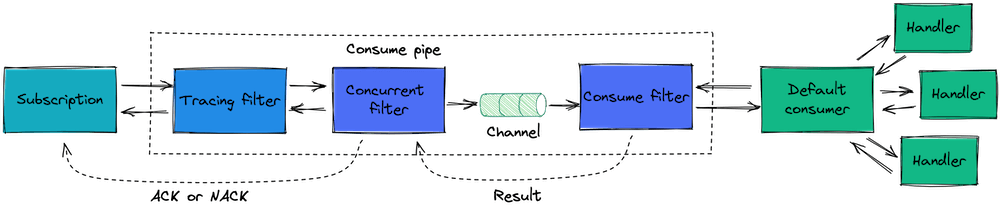
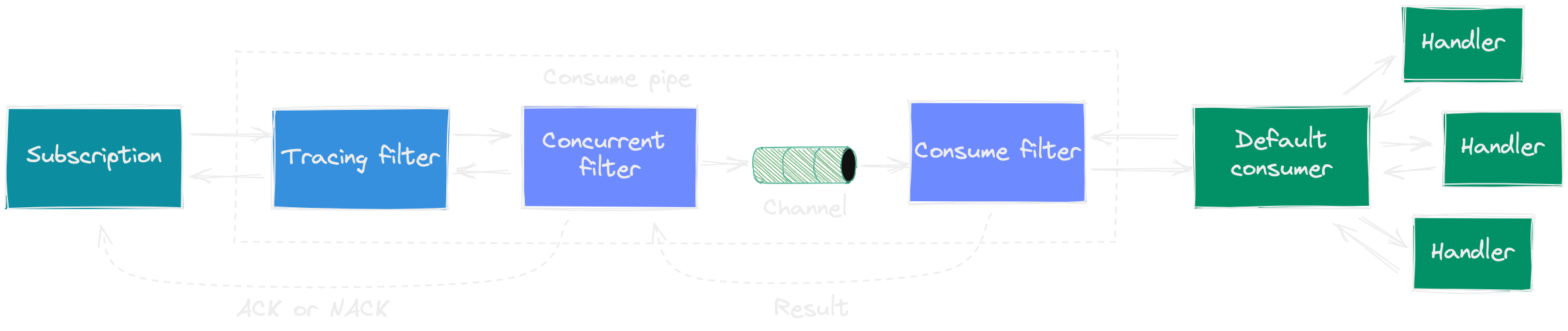
The concurrent filter is useful in combination with partitioning filter, but it can also be used for other purposes, like batched event processing.
Subscriptions that support delayed consume add this filter by default when necessary (based on the subscription configuration). Usually, you'd need to set the ConcurrencyLimit property of the subscription options to a value greater than 1 to enable the concurrent filter.
Do not set the ConcurrencyLimit property when using the partitioning filter.
Partitioning filter
Sometimes the subscription workload gets too high for it to cope with the number of delivered messages, and process them fast enough one by one. In this case, the partitioning filter can be useful as it allows handling messages in parallel. Most of the time you'd want the messages to be delivered in order within some partition. For example, it is often important to process messages from a single aggregate in order. To support that, you can use the stream name (which contains the aggregate id) as the partition key.
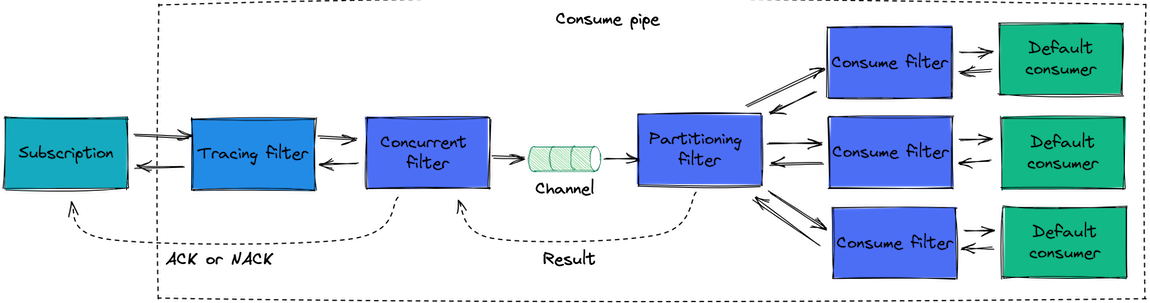
You can use two options for configuring the filter:
- Provide a function that calculates the partition hash
- Provide a function that returns the partition key
- Provide nothing
Using the second option is easier as you don't need to calculate the hash, it's enough to return something like stream id. In that case, the filter will use MurmurHash3 to calculate the hash for a given partition key.
The third option will use the default partition key function that uses the message stream as partition key.
All those options require the number of partitions provided as an argument.
As the partitioning filter processes messages in multiple threads, it cannot provide the global processing order. The order of processing is guaranteed within a partition. Due to that fact, it needs to be able to Ack or Nack messages individually, without maintaining global order. Therefore, it only works with AsyncConsumeContext, and it's often used with the concurrent filter for best performance. As you can imagine, partitioning can only be used for subscriptions that support delayed consume.
Subscriptions that support delayed consume add this filter by default when necessary (based on the subscription configuration) together with the concurrent filter. Check the particular transport subscription implementation to learn more.