Aggregate store
Eventuous does not have a concept of Repository. Find out why on this page.
Eventuous provides a single abstraction for the domain objects persistence, which is the AggregateStore.
The AggregateStore uses the IEventStore abstraction to be persistence-agnostic, so it can be used as-is, when you give it a proper implementation of event store.
We have only two operations in the AggregateStore:
Load- retrieves events from an aggregate stream and restores the aggregate state using those events.Store- collects new events from an aggregate and stores those events to the aggregate stream.
The AggregateStore constructor needs two arguments:
- Event store (
IEventStore) - Event serializer (
IEventSerializer)
Our CommandService uses the AggregateStore in its command-handling flow.
Using EventStoreDB
Eventuous supports EventStoreDB out of the box, but only v20+ with gRPC protocol.
Using this pre-made event persistence is easy. You can register the necessary dependencies in your startup code:
var esdbSettings = EventStoreClientSettings.Create(connectionString);
builder.Services
.AddSingleton(new EventStoreClient(esdbSettings))
.AddAggregateStore<EsdbEventStore>();
The AddAggregateStore extension is available in the Eventuous.AspNetCore NuGet package.
Make sure to read about events serialisation.
Bring your own event store
You can build your own event store, if you want to use a different database. If you have another implementation of IEventStore interface, you can register the aggregate store like this:
builder.Services
.AddSingleton<IEventStore>(new MyEventStore(...))
.AddAggregateStore<MyEventStore>();
Multi-tier store
When you have an event-sourced system in production for a while, you might collect a lot of historical events. Some event streams might be as old, as they won't be frequently accessed, but when using a single event store, you'd have to store all those events in a hot store, as it's the only one you have. It might create an issue of misusing the hot store, as those historical events are expensive to keep.
Eventuous has a feature to store historical events in a separate store, called the Multi-tier store. It works best when combined with a connector, which copies all the events from the hot store to the archive store real-time. Here, you find an example of using Elasticsearch as the archive store.
Archive in real-time
The connector is running continuously, and it copies all the events from the hot store to the archive store. It subscribes to the hot store using a catch-up subscription to the global log, and copies all the events from there to the archive. In this example, we use the Elastic Connector in producer mode to replicate events from the hot store to archive store.
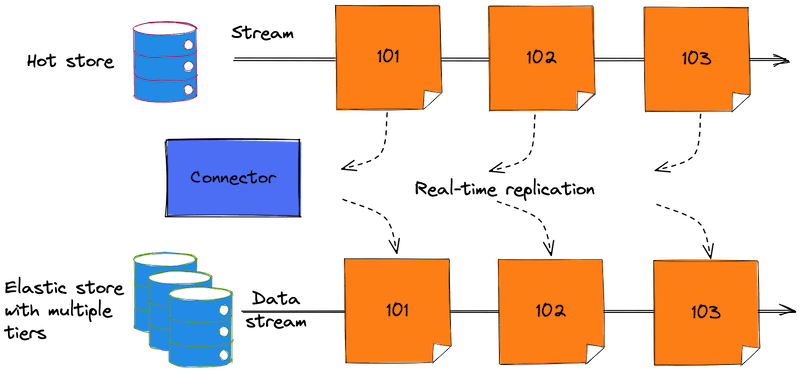
As the connector replicate all the events, there's no need to perform an explicit archive action when storing the events normally using the regular event store.
Delete events from the hot store
Then, to ensure that old events get removed from the hot store, you need to do so on the infrastructure level. For example, you can use the EventStoreDB feature to define the stream TTL (time to live), after which the events are removed from the hot store during the scavenge process.
Right now, there's no built-in support for setting the stream metadata using Eventuous, but it is being built.
When all the bits and pieces are in place, old events will be disappearing from the hot store automatically. Alternatively, you can delete old streams using some scheduled job with a pre-defined retention rules. The archive store will keep all the events forever, unless you delete them manually.
Aggregate store with archive
Now, we need to tell Eventuous to use the archive store. It's done using the AggregateStore<T> class, where T is the archive event reader. To register an aggregate store that uses EventStoreDB as the hot store and Elastic for archive, use the following code:
Elastic is a particularly good candidate for the archive store because it has multi-tier architecture as a native feature, and you can easily set up a cluster with warm, cold, and frozen tiers, so that you pay less to keep the historical events.
// register EventStoreClient
// register IElasticClient
builder.Services.AddAggregateStore<EsdbEventStore, ElasticEventStore>();
The Elastic event reader needs to have a pre-configured index. You'd need to call the following from the bootstrap code:
var indexConfig = new IndexConfig { ... };
var app = builder.Build();
await app.Services.GetRequiredService<IElasticClient>()
.CreateIndexIfNecessary<PersistedEvent>(indexConfig);
Check the Playground example to see how to configure a multi-tiered index with rollover policies.
From there, the process of loading an aggregate is seamless from the outside, but it will work differently.
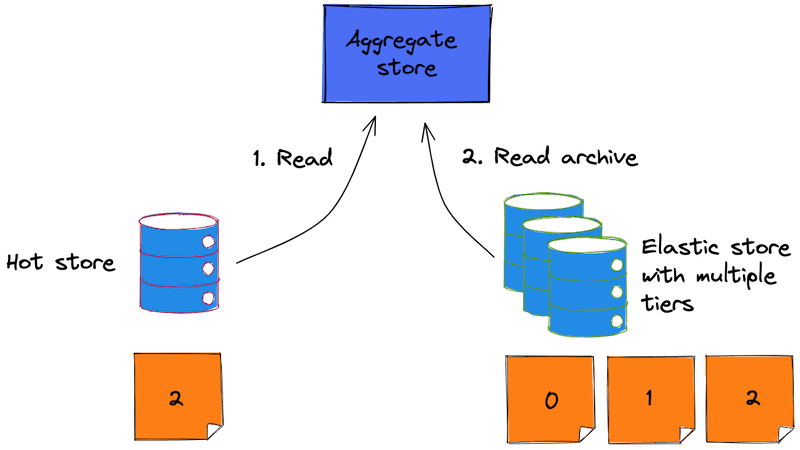
Here's the reading process described step-by-step: 1) First, read the stream from the hot store 2) If the stream doesn't exist, read all the stream events from the archive store 3) If the stream exists, check the first retrieved event number 4) If the number is greater than zero, it means that part of the stream was truncated, so read the rest of the stream from the archive store 5) Combine events from both stores in one collection 6) Select only distinct events using the event version 7) Rehydrate the aggregate using the resulting events collection
As the result, the load operation would be as fast as it would be with the hot store, because when the hot store returns a full stream, the aggregate store won't fall back to the archive store. However, when the aggregate store discovers that the hot store contains an incomplete stream, it will attempt to load the historical events from the archive store. As this process is seamless for the user of the aggregate store, there's no difference on the aggregate store signature.
There is a drawback to this approach. As events disappear from the hot store, you won't be able to replay them when you create new subscriptions that need to process all the historical events. However, you need to carefully examine if this is a problem in your application.
In many cases, replaying the full history is the opposite of what you want. If you add a new subscription to host a new read model, that new read model might only need to process the latest events, and processing the full history would just trigger useless database operations.
For example, if you add an Upcoming check-ins read model, it would need to process events from reservations during the booking period that hasn't completed yet. It's not often that you have reservations that are made five years back, in many cases it's just impossible as hotels set their prices only a year or so upfront. Therefore, projecting the full history of reservations would trigger adding and removing thousands of records to the database, which is not what you want. In fact, if you have only reservation events for the past year, and the rest in the archive, you will have the new read model rebuilt much faster, and the fact that all the historical events are archived won't be noticeable.
Remember that you might decide to use the archive function in your system if you expect it to produce tens of millions events per year, and keep them forever.